

原创
java 集合类详解
了解集合
定义:集合是一个存放对象引用的容器。
集合:长度可变,可以存储不同数据类型的对象引用。(不可存储基本数据类型)
集合概述
图解
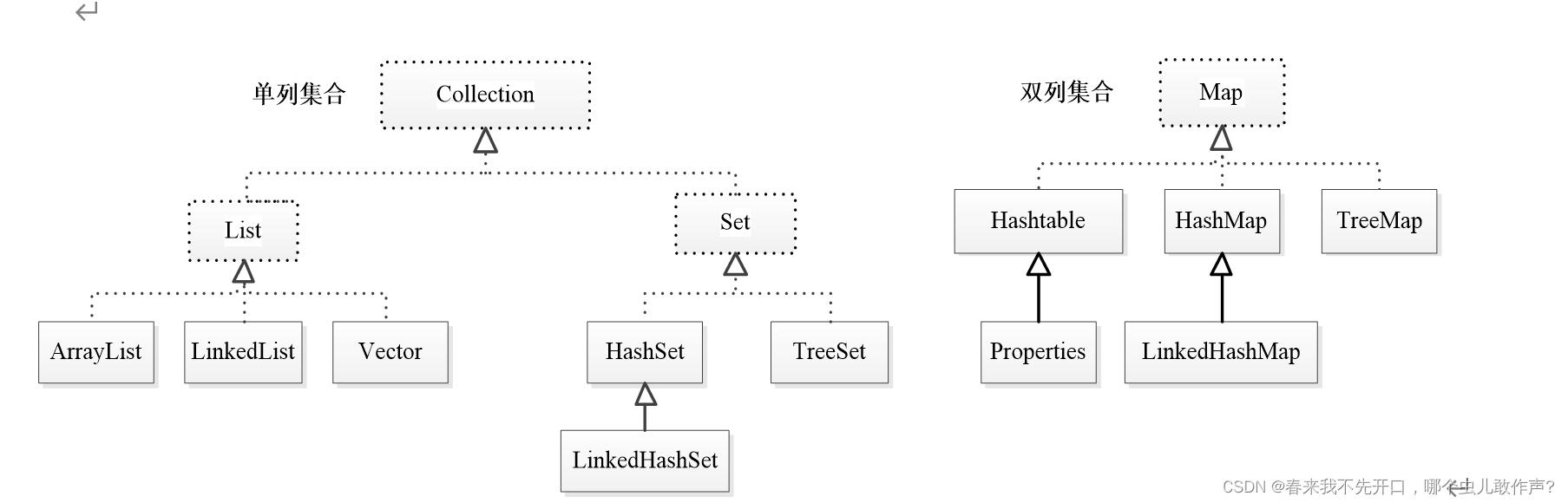
分析:
单列集合:接口Collection
Collection子接口: List 特点:元素有序,存储可重复
List实现类: ArrayList 特点:查找快、增删慢,数组形式
List实现类: LinkedList 特点:增删快、查询慢、双向循环链表结构
Collection子接口: Set 特点:元素无序,存储元素不重复
Set元素是无序(存入和取出的顺序不一定一致),元素不可以重复。Set集合体系没有索引,取出方式是迭代器。
Set实现类: HashSet 特点:底层哈希表、数组、链表、线程非同步。
Set实现类: LInkedHashSet 特点:底层哈希表、数组、双向循环链表。
Set实现类: TreeSet 特点:底层二叉树存储元素,对存储的元素排序(自然排序、定制排序)。
双列集合:接口Map
定义:存储的数据是以键值对的形式存在的,键不可重复,值可以重复。
Map实现类: HashMap 特点: 线程不安全、底层链表+数组+哈希表
Map实现类: TreeMap 特点: 底层红黑树、保证排序(自然排序、定制排序)。
单列集合Collection
单列集合:元素是孤立存在的,向集合中存储元素采用一个个元素的方式存储。
常用方法:

List子接口
特点:可以重复,元素有序(元素的存入和取出顺序一致)。
List实现类: Arrylist 特点:增删慢、查询快、数组形式存储。
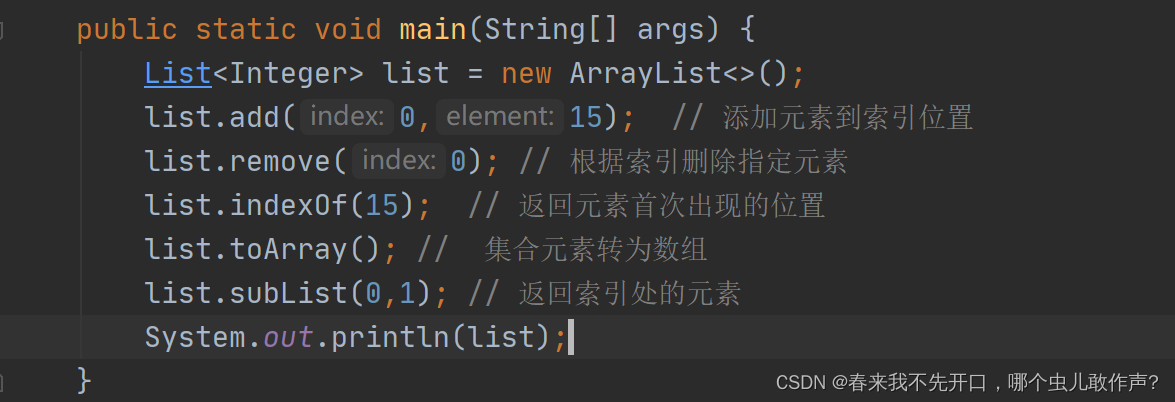
list实现类:LinkedList 特点:增删快、查询慢、双向循环链表结构。
常用方法:(查找Api文档)

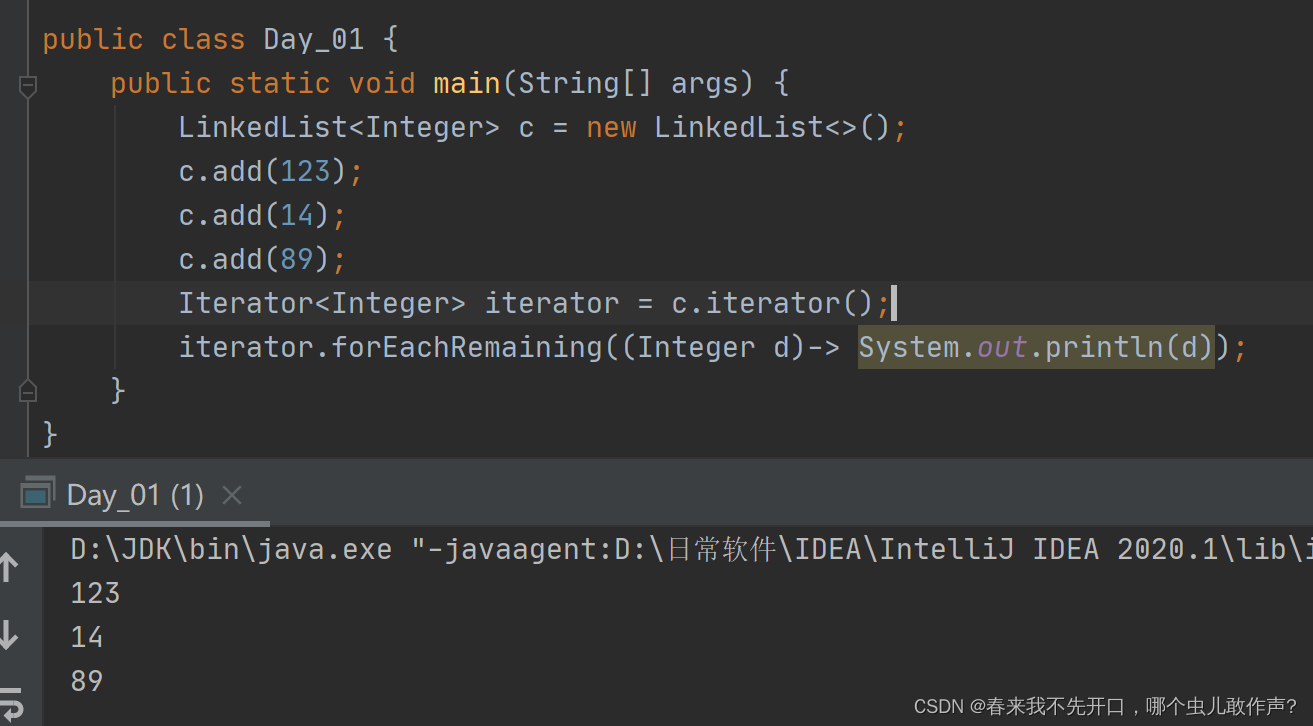
Collection集合遍历
iterator接口 :迭代访问集合中的元素。
iterator存储原理:
图解
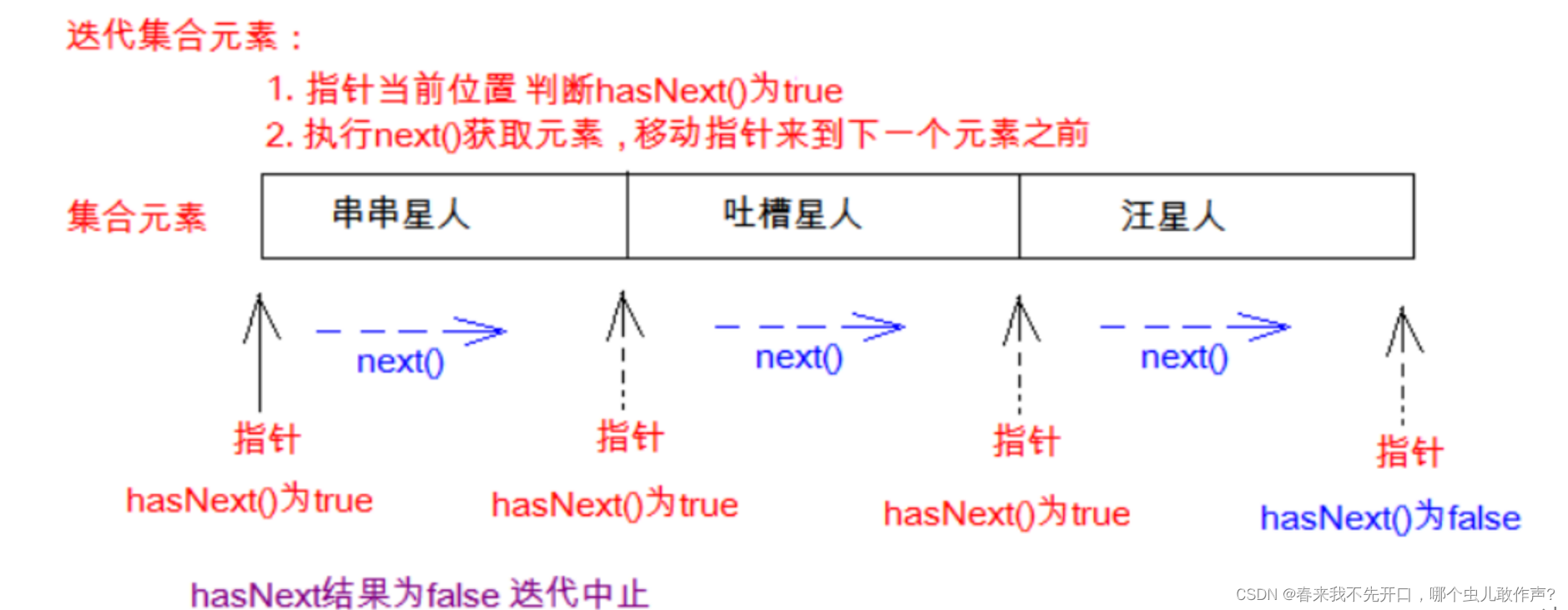
第一种方式:迭代器遍历元素
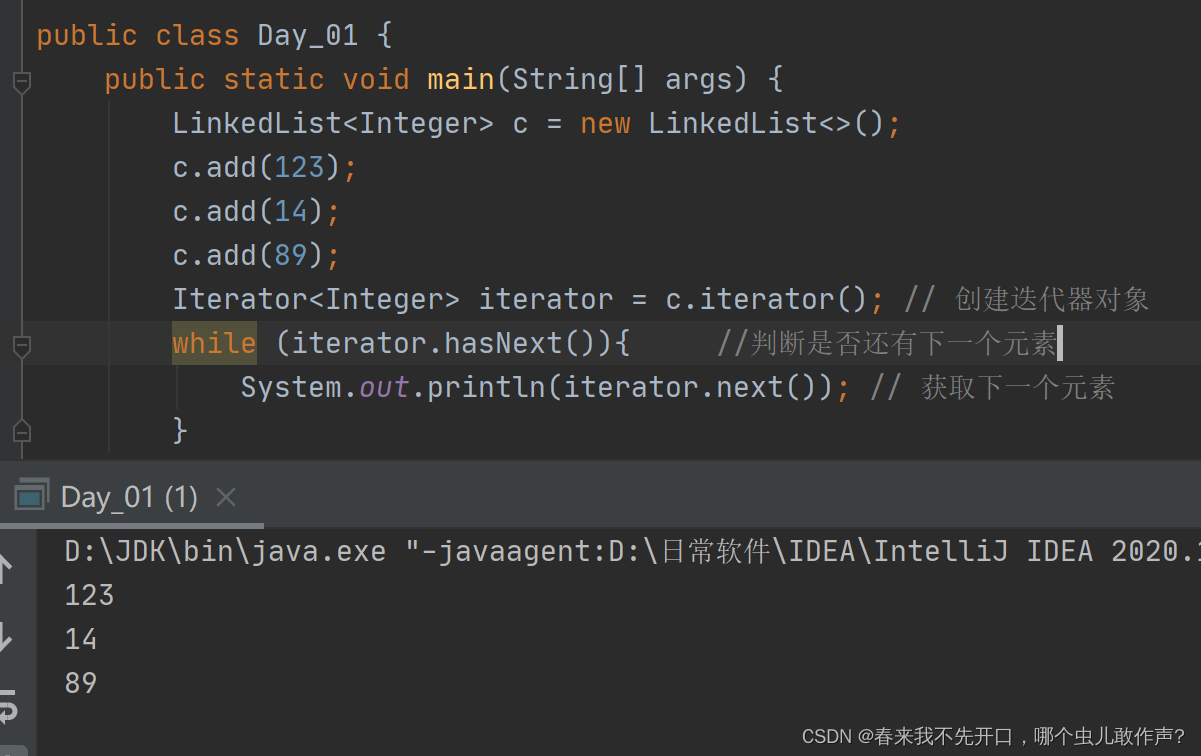
第二种方式:增强for循环

第三种方式:foreach循环遍历

第四种方式:iterator的foreachremaining()方法循环遍历
Set子接口
特点:存入元素不重复,无序(存入顺序和取出顺序不一致)。
实现类HashSet
实现原理
自定义类对象存入HashSet
private String name;
private int age;
public Day_02(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
// 自定义类
public void setAge(int age) {
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Day_02 day_02 = (Day_02) o;
if (age != day_02.age) return false;
return name != null ? name.equals(day_02.name) : day_02.name == null;
}
@Override
public int hashCode() {
int result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
return result;
}
@Override
public String toString() {
return "Day_02{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
// 实现类
public static void main(String[] args) {
HashSet<Day_02> c = new HashSet<>();
Day_02 d1= new Day_02("核潜艇",5);
Day_02 d2= new Day_02("轰炸机",002);
Day_02 d3= new Day_02("核潜艇",5);
c.add(d1);
c.add(d2);
c.add(d3);
System.out.println(c);
}
}
实现类:LinkedHashSet
特点:链表保证存储的顺序和取出顺序一致,元素不重复,哈希表保证的。

TreeSet接口
特点:采用二叉树存储元素
二叉树定义:每个节点最多两个节点的二叉树。
TreeSet存储原理
第一次值,存储在顶端,
第二次值,跟第一次值比较,小存左,大存右边。
第三次值,跟第一次值比较,小存左,大存右边,接着跟第二次值比较。
(有重复的元素,会将重复的元素去掉)
以此类推。
图解:

常用方法:
public static void main(String[] args) {
TreeSet<Integer> c = new TreeSet<>();
c.add(15);
c.add(30);
c.add(18);
System.out.println(c.lower(1)); // 返回集合中小于输入数的最大元素
System.out.println(c.floor(15)); //返回集合中小于或等于输入数的最大元素
System.out.println(c.higher(65));//返回集合中大于输入数的最小元素
System.out.println(c.ceiling(48)); // 返回集合中或与或等于给定元素的最小元素
System.out.println(c.first()); // 返回集合的首个元素
System.out.println(c.pollFirst());//移除并返回集合的第一个元素
}
自然排序: 存储元素必须实现Comparable接口,重写compareTo( )方法
注意:返回值为负数,当前存入的较小值,存左边
返回值为0,存入的元素跟集合元素重复、不存
返回值为正数,存入的元素较大,存右边。
代码:
Day_02类
public class Day_02 implements Comparable<Day_02>{
private String name;
private int age;
public Day_02(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Day_02 day_02 = (Day_02) o;
if (age != day_02.age) return false;
return name != null ? name.equals(day_02.name) : day_02.name == null;
}
@Override
public int hashCode() {
int result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
return result;
}
@Override
public String toString() {
return "Day_02{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
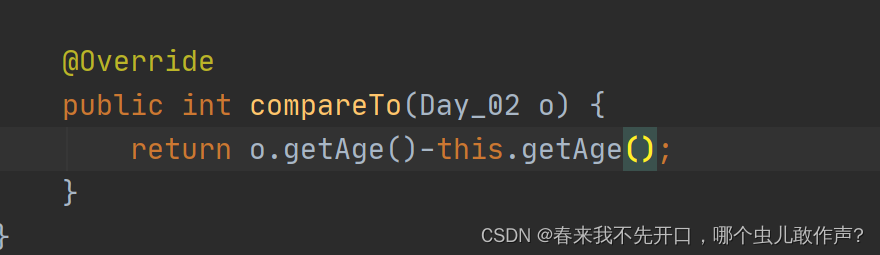
@Override
public int compareTo(Day_02 o) {
return o.age-this.age; // o.age 正在存储的对象年龄 this.age 已经存入的对象年龄
}
}
//测试类
TreeSet<Day_02> c = new TreeSet<>();
Day_02 d1= new Day_02("核潜艇",15);
Day_02 d2 = new Day_02("轰炸机",1);
Day_02 d3= new Day_02("巡洋舰",156);
c.add(d1);
c.add(d2);
c.add(d3);
System.out.println(c);
定制排序:comparator比较器比较
代码:
// Day_02类
public class Day_02 {
private String name;
private int age;
public Day_02(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Day_02 day_02 = (Day_02) o;
if (age != day_02.age) return false;
return name != null ? name.equals(day_02.name) : day_02.name == null;
}
@Override
public int hashCode() {
int result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
return result;
}
@Override
public String toString() {
return "Day_02{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
// 测试类
public static void main(String[] args) {
TreeSet<Day_02> c = new TreeSet<>(new Comparator<Day_02>() {
@Override
public int compare(Day_02 o1, Day_02 o2) {
return o1.getAge()-o2.getAge();
}
});
Day_02 d1= new Day_02("核潜艇",15);
Day_02 d2 = new Day_02("轰炸机",1);
Day_02 d3= new Day_02("巡洋舰",156);
c.add(d1);
c.add(d2);
c.add(d3);
System.out.println(c);
}
双列集合Map接口
Map简介:
特点:Map的映射关系是一个键对象key对应一个值对象value,键不可重复,值可以。
实现类HashMap集合
内部结构

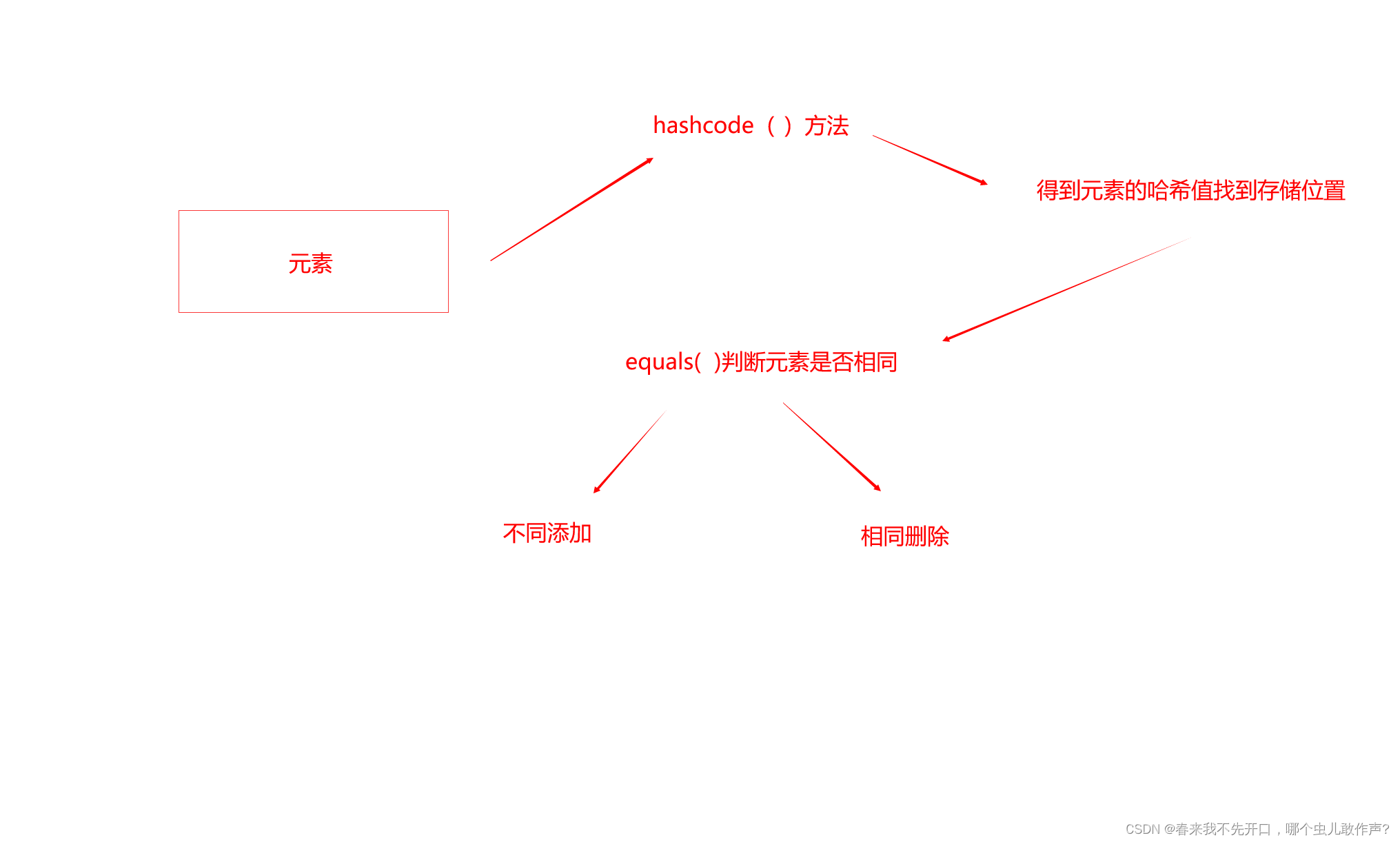
HashMap存储原理:
HashCode( )方法计算哈希值找到存储位置,equals( )比较键内容是否重复。
哈希值不同,键内容不同,直接插入。
哈希值相同,键内容不同,往下插入(水桶状)
哈希值相同,键内容相同,删除。
Map常用方法:
public static void main(String[] args) {
HashMap<String,String> c = new HashMap<>();
c.put("核潜艇","轰炸机");
c.put("隐形轰炸机","巡洋舰");
c.put("突击航母","驱逐舰");
System.out.println(c.size()); // 返回键值映射的个数
System.out.println(c.containsValue("驱逐舰")); // 判断是否存在值
System.out.println(c.containsKey("潜艇")); // 判断是否存在键
System.out.println(c.remove("潜艇")); // 删除指定键元素
c.clear(); // 删除真个集合元素
Set<String> strings = c.keySet(); // Set集合的形式返回这个Map集合的所有键对象
}
Map集合遍历
第一种方式:keySet( )方法
public static void main(String[] args) {
HashMap<String,String> c = new HashMap<>();
c.put("核潜艇","轰炸机");
c.put("隐形轰炸机","巡洋舰");
c.put("突击航母","驱逐舰");
Set<String> strings = c.keySet(); // 获取map集合所有的键对象
for (String a:strings){
System.out.println(c.get(a)+a); // get( )获取键
}
第二种方式 entrySet ( ) iterator( )
public static void main(String[] args) {
HashMap<String,String> c = new HashMap<>();
c.put("核潜艇","轰炸机");
c.put("隐形轰炸机","巡洋舰");
c.put("突击航母","驱逐舰");
Iterator<Map.Entry<String, String>> iterator = c.entrySet().iterator();
while (iterator.hasNext()){
Map.Entry<String, String> next = iterator.next();
String key = next.getKey();
String value = next.getValue();
System.out.println(key+value);
}
}
第三种方式 forEach( )
public static void main(String[] args) {
HashMap<String,String> c = new HashMap<>();
c.put("核潜艇","轰炸机");
c.put("隐形轰炸机","巡洋舰");
c.put("突击航母","驱逐舰");
Iterator<Map.Entry<String, String>> iterator = c.entrySet().iterator();
while (iterator.hasNext()){
Map.Entry<String, String> next = iterator.next();
String key = next.getKey();
String value = next.getValue();
System.out.println(key+value);
}
}
第四种方式 获取值 values( )
public static void main(String[] args) {
HashMap<String, String> c = new HashMap<>();
c.put("核潜艇", "轰炸机");
c.put("隐形轰炸机", "巡洋舰");
c.put("突击航母", "驱逐舰");
Collection<String> values = c.values();
values.forEach((String a)-> System.out.println(a));
}
Map实现类TreeMap
自然排序 : 实现comparable 接口 重写 CompareTo( )方法

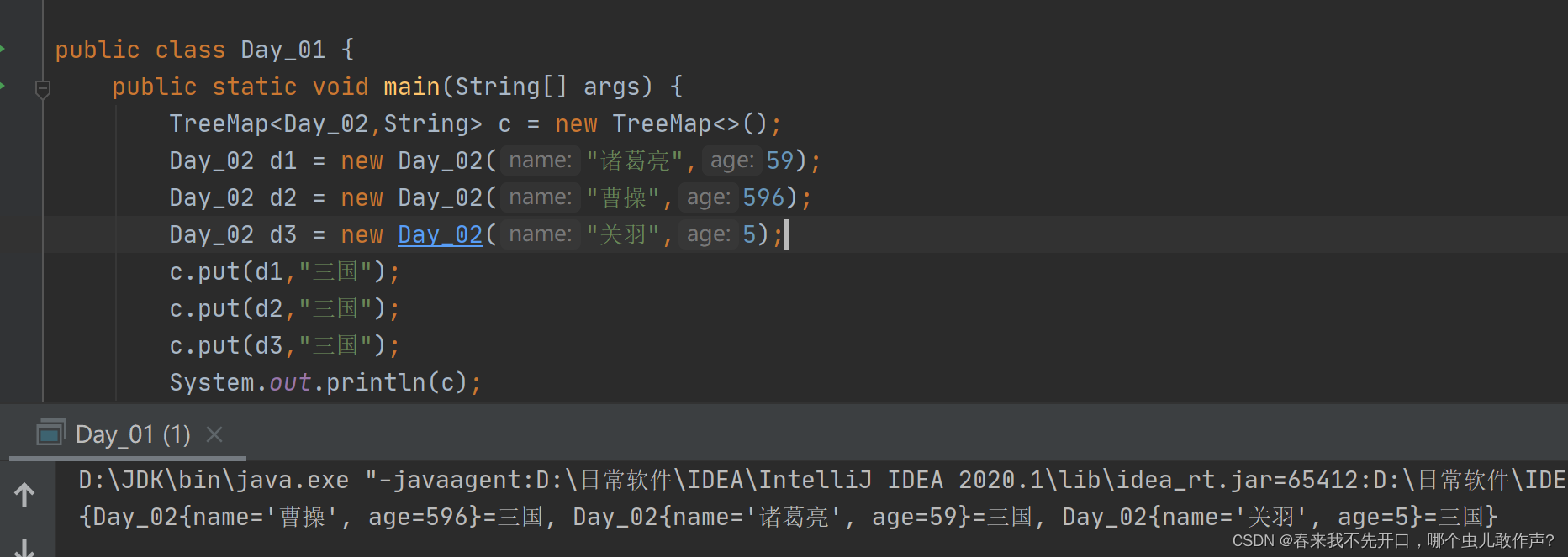
定制排序
new Comparator( )
Properties集合
定义:properties 集合继承于Hashtable,表示一个持久的属性集。
作用:主要用来存储字符串类型的键和值
区别: Hashtable 是线程安全的
常用工具类
Collections工具类(对单列集合操作)
作用:提供大量静态方法对集合元素进行排序、查找、修改。
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
Collections.addAll(list, "a", "b", "c"); // 集合中添加元素
Collections.shuffle(list); // 随机排序集合中元素
Collections.reverse(list); // 反转集合元素
Collections.sort(list); //集合中元素进行自然排序
}
Arrays工具类
作用:对数组操作的静态方法
public static void main(String[] args) {
int[] arr = {15, 6, 5, 6, 5};
Arrays.sort(arr); // 数组元素进行自然排序
System.out.println(Arrays.toString(arr)); // 打印数组元素
System.out.println(Arrays.binarySearch(arr, 6)); // 求数组元素的索引值 (先sort( )排序在求值)
int[] ints = Arrays.copyOfRange(arr, 1, 2); // arr数组元素复制到ints数组
Arrays.fill(ints,26); // ints的所有元素替换为26
}



评论
登录后才可以进行评论哦!